1. Redis 简介
Redis(Remote Dictionary Server)是一个开源的非关系型内存数据库系统,它以键值对(key-value)的形式存储数据。Redis支持多种数据结构,包括字符串(String)、哈希(Hash)、列表(List)、集合(Set)、有序集合(Sorted Set)等。
2. Redis 的应用场景
2.1. Redis作为后端数据库
当 Redis 作为后端数据库时,它负责存储和管理应用程序的数据。这意味着所有的数据都直接存储在 Redis中,而不需要使用其他数据库。这种方式适用于一些简单的应用场景,其中数据量较小且不需要复杂的查询和事务支持。
Redis作为后端数据库的优势:
- 高性能和低延迟:Redis将数据存储在内存中,以实现快速的读写操作,具有出色的性能和低延迟。
- 丰富的数据结构:Redis支持多种数据结构,如字符串、哈希、列表、集合和有序集合,使得它可以灵活地存储和操作不同类型的数据。
- 持久化支持:Redis支持数据持久化,可以将数据保存到磁盘上,以便在重启后恢复数据。
Redis作为后端数据库的劣势:
- 有限的存储容量:由于Redis将数据存储在内存中,存储容量受到内存大小的限制。对于大规模的数据存储需求,可能需要考虑其他数据库解决方案。
- 缺乏复杂查询和事务支持:相比传统的关系型数据库,Redis的查询和事务支持相对较弱。如果应用程序需要复杂的查询操作或需要强大的事务支持,可能需要考虑其他数据库。
2.2. Redis作为数据库缓存
当 Redis 作为数据库缓存时,它位于应用程序和后端数据库之间,用于缓存常用的数据。应用程序首先检查 Redis 缓存,如果数据存在,则直接从 Redis 中获取;如果数据不存在,则从后端数据库中获取,并将数据存储到 Redis 缓存中,以供后续使用。
Redis作为数据库缓存的优势:
- 提高读取性能:由于Redis将数据存储在内存中,读取数据的速度非常快。通过将常用的数据缓存到Redis中,可以大大提高读取性能和响应速度。
- 减轻后端数据库负载:通过使用Redis缓存,可以减少对后端数据库的频繁读取请求,从而减轻数据库的负载,提高整体系统的性能和可扩展性。
- 灵活的缓存策略:Redis提供了灵活的缓存策略,可以根据数据的访问模式和需求进行缓存设置,如设置过期时间、LRU(最近最少使用)淘汰策略等。
2.3. 引入Redis作为数据库缓存的目的
思考:以MySQL为例,MySQL本身就自带内存优化机制,为何还要引入Redis?
MySQL数据库缓存机制了解:
- 查询缓存(Query Cache):
MySQL的查询缓存可以缓存查询语句的结果集,以避免重复执行相同的查询。当启用查询缓存时,MySQL会将查询语句及其结果存储在内存中,下次执行相同的查询时,如果查询语句和查询缓存中的内容完全匹配,则直接返回缓存的结果,而不需要再次执行查询。- 优点:查询缓存的优点是简单易用,对于一些频繁执行相同查询的场景可以提供较好的性能提升。
- 缺点:
- 查询缓存对于复杂查询、包含动态参数的查询或更新频繁的表不适用。
- 当有任何对表的更新操作(INSERT、UPDATE、DELETE)时,与该表相关的查询缓存都会被清除,导致缓存命中率下降。
- 查询缓存的内存管理和维护也会带来一定的开销。
- 由于以上限制和问题,MySQL 5.7版本开始,默认情况下不再启用查询缓存,并且在MySQL 8.0版本中已经完全移除了查询缓存。
- InnoDB缓冲池(InnoDB Buffer Pool):
InnoDB是MySQL的一种存储引擎,它具有自己的缓存机制,称为InnoDB缓冲池。InnoDB缓冲池是一个内存区域,用于缓存数据库表的数据和索引。此缓存方式不受SQL语句的影响只要数据缓存在内存,那么数据查询就会命中。- InnoDB缓冲池的大小可以通过配置参数
innodb_buffer_pool_size进行调整。适当调整缓冲池的大小可以提高查询性能,减少磁盘IO操作。 - 相比查询缓存,InnoDB缓冲池更加灵活和高效,适用于各种查询场景,并且不受查询缓存的限制和问题。因此,在现代的MySQL版本中,通常推荐使用InnoDB缓冲池作为主要的数据库缓存机制。
- InnoDB缓冲池的大小可以通过配置参数
MySQL数据库缓存机制的局限性:
- MySQL自带内存优化机制,是受限于MySQL所在的机器的物理内存容量的
- 相比MySQL的内存优化机制,Redis的读取性能更高。
- MySQL在读取数据的过程中,这条查询会一直阻塞在原地,直到读取完成。所以,在高并发场景下针对热点数据,会积压很多用户请求阻塞在原地,压力过大会导致MySQL服务器挂掉,压力会分散给其他的MySQL服务器,可能会导致其他MySQL服务器也跟着一起挂掉形成雪崩效应/曲线掉底。
引入Redis目的:
- 高性能读取: Redis作为内存数据库,读取数据的速度非常快。通过将常用的数据缓存到Redis中,可以大大提高读取性能和响应速度。相比MySQL的内存优化机制,Redis的读取性能更高。
- 减轻数据库负载: 通过使用Redis缓存,可以减少对MySQL数据库的频繁读取请求,从而减轻数据库的负载,提高整体系统的性能和可扩展性。Redis可以作为一个独立的缓存层,将读取请求分担到Redis,减少对MySQL的直接访问。
- 灵活的缓存策略: Redis提供了灵活的缓存策略,可以根据数据的访问模式和需求进行缓存设置,如设置过期时间、LRU(最近最少使用)淘汰策略等。这使得开发人员可以更精细地控制缓存的行为,以适应不同的应用场景。
- 分布式缓存: Redis可以轻松地进行分布式部署,支持主从复制和哨兵机制,以实现高可用性和故障转移。这使得Redis可以扩展到多个节点,提供更高的并发处理能力和容错性。
- 多样化的数据结构: Redis支持多种数据结构,如字符串、哈希、列表、集合和有序集合,使得它可以灵活地存储和操作不同类型的数据。这使得Redis在某些场景下比MySQL更适合存储和处理特定类型的数据。
结论:
当数据量不大时则可以不引入Redis,当数据量过大MySQL缓存池不能容纳这么多数据时,可以引入Redis单独作为一个缓存层,提升数据读取速度,提高用户体验。
3. Redis 读取数据快的原因
- 内存存储: Redis将数据存储在内存中,而不是磁盘上。相比于磁盘访问,内存访问速度更快,因为内存的读取速度比磁盘快几个数量级。这使得Redis能够以非常低的延迟提供快速的数据读取。
- 简单的数据结构: Redis使用简单的键值对(key-value)数据结构,这种数据结构非常高效。通过使用哈希表等数据结构,Redis可以在O(1)的时间复杂度内进行数据查找和读取操作,无论数据量的大小。
- 单线程模型: Redis采用单线程的事件驱动模型,通过事件循环机制处理客户端请求。这种单线程模型避免了多线程之间的竞争和同步开销,简化了数据访问的逻辑,提高了读取性能。
- 高效的网络通信: Redis使用基于TCP的协议进行与客户端的通信。它采用了高效的I/O多路复用模型(epoll),可以同时处理多个客户端请求,减少了网络通信的开销。
- 高效的内存管理机制:
- 内存分配和释放: Redis使用自己的内存分配器,称为jemalloc,默认情况下,它会预分配一块大内存,并将其切分为多个小块,以减少内存碎片化。Redis还使用了对象池技术,通过重复使用已分配的对象,减少了内存分配和释放的开销。
- 内存压缩: Redis在存储数据时,会对字符串类型的数据进行内存压缩。当一个字符串对象的长度小于一定阈值时,Redis会使用特殊的编码方式来存储,以减少内存的占用。
- 内存回收: Redis使用引用计数(Reference Counting)和定期回收机制来管理内存的释放。引用计数用于跟踪对象的引用数量,当引用计数为0时,表示对象不再被使用,可以释放内存。定期回收机制会周期性地检查对象的引用计数,并释放不再使用的对象所占用的内存。
- 内存淘汰策略: 当Redis的内存达到配置的上限时,为了保证内存的可用性,需要进行内存淘汰。Redis提供了多种内存淘汰策略,如LRU(最近最少使用)、LFU(最不经常使用)、随机等。这些策略可以根据数据的访问模式和需求,选择合适的方式来淘汰内存中的数据。
- 内存优化配置: Redis提供了一些内存优化的配置选项,如maxmemory参数用于限制Redis使用的最大内存大小,maxmemory-policy参数用于配置内存淘汰策略等。通过合理配置这些选项,可以根据实际需求来优化内存的使用。
4. Redis 6.x 版本的多线程介绍
Redis 6.x 版本引入的多线程机制是其架构的重大革新,主要针对网络 I/O 处理进行优化,但仍保持命令执行的单线程特性。
多线程模型架构图:
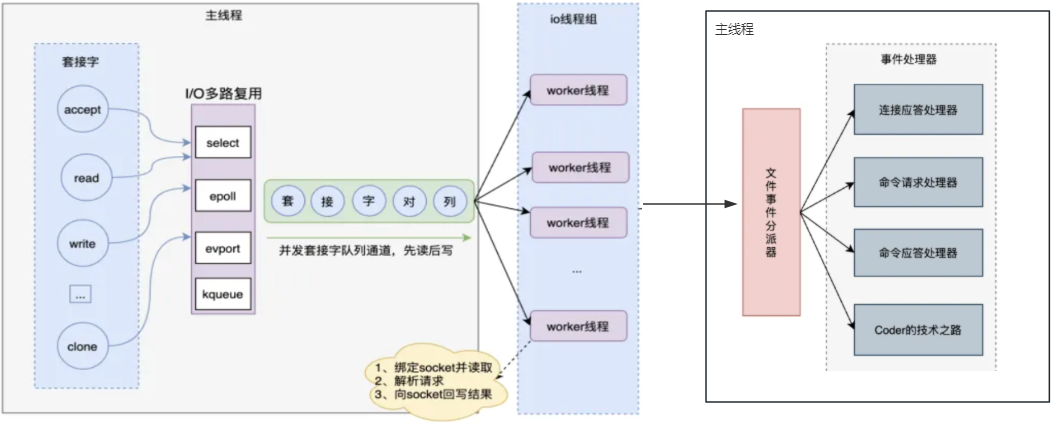
命令执行仍保持单线程(避免竞态条件),仅在网络 I/O和协议解析这部分使用多线程。详解如下:
- 原理:在 Redis 6.0 之前,尽管它的内存管理非常高效,单线程模型也能提 供惊人的速度。但 Redis 的瓶颈并非在于内存,而在于网络I/O模块耗费的时间。Redis 6.0 引入多线程来处理网络I/O,从而使得CPU资源得到充分利用,减少了网络I/O阻塞所产生的性能损失。
Redis 的这种多线程模型,特别是在处理大量并发请求时,可以显著提高 Redis 的性能。在很多场景中,当I/O多线程功能开启时,配合适当的线程数配置,Redis 的新版本可以在单实例上提供2倍于之前的操作处理能力。 需要注意的是,虽然启用了I/O多线程,但 Redis 的数据操作仍然是单线程的,,不会因为多线程而出现数据不一致的问题。