1. 监控概念
监控在维护应用程序和基础设施的性能、可靠性和安全性方面起着至关重要的作用。它涉及收集、分析和可视化数据,以获取有关性能、可用性和安全性的见解。监控包括基础设施监控、应用程序性能监控(APM)、日志监控、安全监控和网络监控等不同类型。各种工具如 Prometheus、Grafana、ELK Stack、Nagios、AppDynamics、New Relic 和 PagerDuty 用于有效的监控。
2. 监控的两大分类
监控分为黑盒监控和白盒监控两种不同的监控方法,它们在监控对象和监控方式上有所区别:
- 黑盒监控(Black Box Monitoring)
- 监控对象: 黑盒监控是从外部系统的角度监控系统的行为和性能,类似于将系统视为一个黑盒子,只关注系统的输入和输出,而不考虑内部实现细节。
- 监控方式: 黑盒监控通常通过模拟用户行为或发送请求来测试系统的响应时间、可用性和功能。它主要关注系统对外部请求的处理情况,而不关心系统内部的运行状态。
- 白盒监控(White Box Monitoring)
- 监控对象: 白盒监控是从系统内部的角度监控系统的运行状态和性能,类似于打开系统的白盒子,可以查看系统的内部实现和运行情况。
- 监控方式: 白盒监控通过监视系统的内部指标、日志和性能数据来评估系统的运行状况。它可以提供更详细和深入的信息,帮助识别系统内部的问题和优化性能。
3. Prometheus 介绍
Prometheus 最初是由 SoundCloud 公司开发的开源监控系统,主要用于记录和查询时序性能数据,目前是一个独立的开源项目。Prometheus 在2016年加入 CNCF,是继 Kubernetes 之后第2个 CNCF 托管项目,同时也是 CNCF 中第2个毕业的项目,在容器和微服务领域得到了广泛应用。
Prometheus 的主要特点如下:
- 使用指标名称及键值对标识的多维度数据模型。
- 采用灵活的查询语言 PromQL。
- 不依赖分布式存储,为自治的单 Node 服务。
- 使用 HTTP 完成对监控数据的采集。
- 支持通过一个代理网关(Push Gateway)来推送时序数据。
- 支持通过服务发现或静态配置来发现采集目标。
- 支持多种图形和 Dashboard 的展示,例如 Grafana。
Prometheus 生态系统中的各种组件:
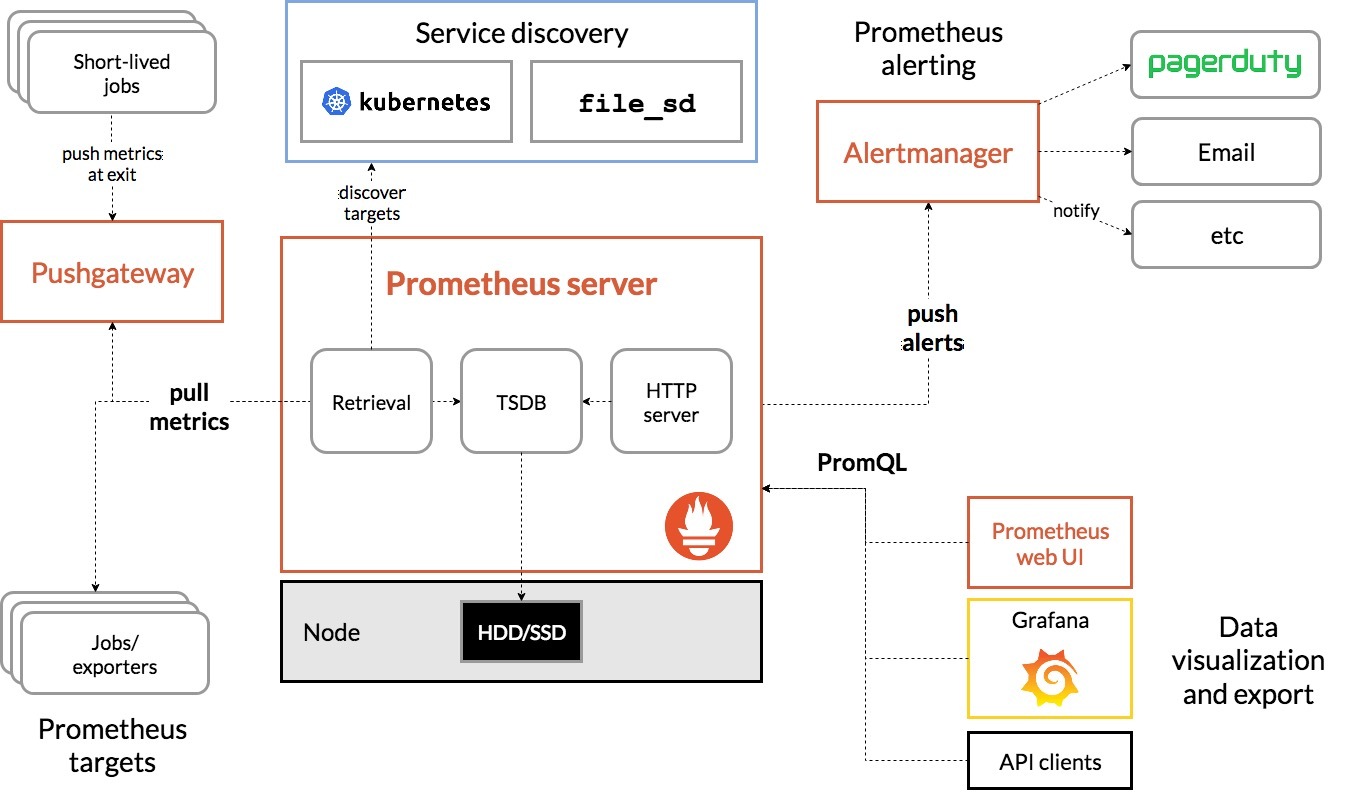
- Prometheus Server:负责监控数据采集和时序数据存储,并提供数据查询功能。
- 时间序列数据是指按时间顺序索引的一系列数据点。
- 客户端 SDK:对接 Prometheus 的开发工具包。
- Push Gateway:对于没有实现 Prometheus 采集接口的应用,可以将性能数据推送到该网关进行代理,然后 Prometheus 从该网关采集数据。
- 第三方 Exporter:各种外部指标收集系统,其数据可以被 Prometheus 采集。
- AlertManager:告警管理器。
4. Prometheus 安装
最新版和长期稳定版二进制包下载地址:https://prometheus.io/download
历史版本下载地址:https://github.com/prometheus/prometheus/tags
wget https://github.com/prometheus/prometheus/releases/download/v2.53.3/prometheus-2.53.3.linux-amd64.tar.gz
tar -xf prometheus-2.53.3.linux-amd64.tar.gz
mkdir /monitor
mv prometheus-2.53.3.linux-amd64 /monitor
ln -s /monitor/prometheus-2.53.3.linux-amd64 /monitor/prometheus
# 创建 tsdb 数据目录
mkdir -p /monitor/prometheus/data
# 添加系统服务
cat > /usr/lib/systemd/system/prometheus.service << 'EOF'
[Unit]
Description=prometheus server daemon
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
# 建议创建一个专门的用户和组,例如 'prometheus'
# User=prometheus
# Group=prometheus
Restart=on-failure
ExecStart=/monitor/prometheus/prometheus \
--config.file=/monitor/prometheus/prometheus.yml \
--storage.tsdb.path=/monitor/prometheus/data \
--storage.tsdb.retention.time=30d \
--web.enable-lifecycle
# 如果启用了 User=prometheus,则需要确保该用户对路径有权限
# 可选:设置文件描述符限制等
# LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
systemctl status prometheus
netstat -tunalp |grep 90905. Prometheus 使用示例
yum install golang -y
# 从 GitHub 上克隆 Prometheus 的 Golang 客户端库到当前目录
git clone https://github.com/prometheus/client_golang.git
cd client_golang/examples/random
# 设置环境变量 GO111MODULE 为 on,启用 Go Modules 支持
export GO111MODULE=on
# 设置环境变量 GOPROXY 为https://goproxy.cn,指定使用 Go Module 代理
export GOPROXY=https://goproxy.cn
# 编译当前目录下的 Go 代码,生成一个名为 random 的二进制可执行文件
go build
# 然后在 3 个独立的终端里面运行 3 个服务
./random -listen-address=:8080 & # 对外暴漏http://localhost:8080/metrics
./random -listen-address=:8081 & # 对外暴漏http://localhost:8081/metrics
./random -listen-address=:8082 & # 对外暴漏http://localhost:8080/metrics
# 因为都对外暴漏了/metrics接口,并且数据格式遵循 prometheus 规范,所以我们可以在 prometheus.yml 中添加监控项
scrape_configs:
# 定义一个名为 'example-random' 的抓取任务(Job)
- job_name: 'example-random'
# 抓取间隔配置:覆盖全局默认抓取间隔,此任务每5秒抓取一次目标指标
# 全局配置通常在 global.scrape_interval 中设置
scrape_interval: 5s
# 静态目标配置:手动指定要监控的目标端点列表
static_configs:
# 第一组目标:包含两个监控目标端点
- targets: ['192.168.2.202:8080', '192.168.2.202:8081']
# 为此组目标添加标签:所有这组目标都会附加 group="production" 标签
# 这有助于在Prometheus中区分不同环境或分组的目标
labels:
group: 'production'
# 第二组目标:包含一个监控目标端点
- targets: ['192.168.2.202:8082']
# 为此目标添加标签:标记为 canary 组(通常是金丝雀发布或测试环境)
labels:
group: 'canary'
# 重启服务
systemctl restart prometheus
# 此示例 prometheus 在 192.168.2.201,客户端所在的主机为 192.168.2.202
# 所以查看页面 http://192.168.2.201:9090/ 点击Status---》Targets,发现有新增的监控job6. 在 k8s 环境部署 Prometheus
部署之前停掉上述步骤部署的二进制版本
systemctl stop prometheus
systemctl disable prometheus创建名称空间
kubectl create namespace monitor创建基础配置文件
# prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s # Prometheus 每隔15s就会从所有配置的目标端点抓取最新的数据
scrape_timeout: 15s # 某个抓取操作在 15 秒内未完成,会被视为超时,不会包含在最新的数据中。
evaluation_interval: 15s # # 每15s对告警规则进行计算
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 部署
kubectl apply -f prometheus-cm.yaml 创建持久卷
# prometheus-pv-pvc.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-local
labels:
app: prometheus
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master-03-u-203
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: monitor
spec:
selector:
matchLabels:
app: prometheus
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: local-storage
# 在 pv 所亲和的节点上创建
sudo mkdir -p /data/k8s/prometheus
kubectl apply -f prometheus-pv-pvc.yaml添加相应权限
# prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ''
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- 'extensions'
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs: # 用来对非资源型 metrics 进行操作的权限声明
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole # 由于我们要获取的资源信息,在每一个 namespace 下面都有可能存在,所以我们这里使用的是 ClusterRole 的资源对象
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
# 部署
kubectl apply -f prometheus-rbac.yaml创建 Deployment 资源
# prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
securityContext: # 增加这一段
runAsUser: 0
containers:
- image: prom/prometheus:v2.53.3 # 也可以是prom/prometheus:v2.53.0
name: prometheus
args:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus' # 指定tsdb数据路径
- '--storage.tsdb.retention.time=24h'
- '--web.enable-admin-api' # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- '--web.enable-lifecycle' # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: '/etc/prometheus'
name: config-volume
- mountPath: '/prometheus'
name: data
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- configMap:
name: prometheus-config
name: config-volume
# 部署
kubectl apply -f prometheus-deploy.yaml创建 Service
# prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: 9090
#targetPort: http
# 部署
kubectl apply -f prometheus-svc.yaml添加监控项
# 添加监控项,然后 apply -f 更新配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s # Prometheus每隔15s就会从所有配置的目标端点抓取最新的数据
scrape_timeout: 15s # 某个抓取操作在 15 秒内未完成,会被视为超时,不会包含在最新的数据中。
evaluation_interval: 15s # # 每15s对告警规则进行计算
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: 'example-random'
scrape_interval: 5s
static_configs:
- targets: ['192.168.2.202:8080', '192.168.2.202:8081']
labels:
group: 'production'
- targets: ['192.168.2.202:8082']
labels:
group: 'canary'重载配置文件
# 查看 prometheus 容器 IP
kubectl -n monitor get pods -o wide
# 重载服务
curl -X POST "http://10.244.4.8:9090/-/reload"
# 访问
## 查看 NodePort
kubectl -n monitor get svc -o wide
## 在浏览器中以集群任意节点IP:NodePort 访问7. 监控 target 三大分类
经过上面的步骤我们在 k8s 集群中部署了一个监控软件,接下来我们来了解一下监控目标的分类。
在监控系统中,监控的目标(target)通常可以分为三大分类,包括主机监控、系统服务监控和应用程序监控。
- 主机监控:主机监控是指对服务器主机的监控,包括监控主机的硬件资源利用率(如 CPU、内存、磁盘、网络等)、操作系统的运行状态、主机的负载情况等。主机监控可以帮助管理员了解主机的健康状况,及时发现并解决主机性能问题,确保主机的稳定运行。
- 系统服务监控:监控操作系统级别的服务、守护进程和基础设施组件的状态,包括监控服务的运行状态、响应时间、可用性、错误率等指标。
- 应用程序监控:应用程序监控是指对应用程序的监控,包括监控应用程序的性能指标、业务指标、用户体验等。
上述三类监控目标的配置有两种配置:
- 动态发现:本质就是通过标签或注解信息进行筛选,符该规则都会被选出来作为 prometheus 监控对象。
- 静态配置:静态配置是直接在 Prometheus 配置文件中明确列出所有要监控的目标地址。
- 监控对象必须暴露一个 /metrics 接口,prometheus server 朝该接口发请求,则会返回固定格式的数据。
注意:有的监控对象有现成的 /metrics 接口可用,没有则需要部署第三方 exporter 来采集指标并暴漏该接口。
7.1 静态配置示例
服务自带 /metrics 接口示例
# 以 k8s 中的 coredns 为例
# 在配置文件中增加下述监控项,然后 apply -f 重载配置
- job_name: "coredns"
static_configs:
- targets: ["kube-dns.kube-system.svc.cluster.local:9153"]
kubectl apply -f prometheus-cm.yaml
curl -X POST "http://10.244.4.8:9090/-/reload"
# 在浏览器中以集群任意节点IP:NodePort 访问可以看到 coredns 的监控项部署 exporter 示例
exporter 官网地址:https://prometheus.io/docs/instrumenting/exporters/
# 安装 redis
yum install redis -y
sed -ri 's/bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
sed -ri 's/port 6379/port 16379/g' /etc/redis.conf
cat >> /etc/redis.conf << "EOF"
requirepass 123456
EOF
systemctl restart redis
systemctl status redis
# 部署 redis_exporter 来采集 redis 的监控信息
wget https://github.com/oliver006/redis_exporter/releases/download/v1.61.0/redis_exporter-v1.61.0.linux-amd64.tar.gz
# 安装
tar xf redis_exporter-v1.61.0.linux-amd64.tar.gz
mv redis_exporter-v1.61.0.linux-amd64/redis_exporter /usr/bin/
# 制作系统服务
cat > /usr/lib/systemd/system/redis_exporter.service << 'EOF'
[Unit]
Description=Redis Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/bin/redis_exporter --redis.addr=redis://127.0.0.1:16379 --redis.password=123456 --web.listen-address=0.0.0.0:9122 --exclude-latency-histogram-metrics
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl restart redis_exporter
systemctl status redis_exporter
# 增加监控项
- job_name: "redis-server"
static_configs:
- targets: ["192.168.2.201:9122"] # 部署 redis_exporter 的主机IP
kubectl apply -f prometheus-cm.yaml
curl -X POST "http://10.244.4.8:9090/-/reload"如果你的 redis-server 部署在 k8s 中,那我们通常不会像上面一样裸部署一个 redis_exporter ,而是会以 sidecar 的形式将 redis_exporter 和主应用 redis_server 部署在同一个 Pod 中,如下所示:
# prome-redis.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: monitor
spec:
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
apiVersion: v1
kind: Service
metadata:
name: redis
namespace: monitor
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
然后你就可以用该 svc 的 clusterip:9121 来访问 /metrics 接口。
kubectl get -n monitor svc -o wide
redis ClusterIP 10.105.23.132 <none> 6379/TCP,9121/TCP 69s app=redis
# 添加监控项
- job_name: 'redis'
static_configs:
- targets: ['redis:9121']
kubectl apply -f prometheus-cm.yaml
curl -X POST "http://10.244.4.8:9090/-/reload"物理节点监控示例
裸部署时需要在每一个物理节点都部署一个 node_exporter 服务。
在 k8s 集群部署时可以使用 DaemonSet 控制器,保证每一个节点都有一个 node_exporter 服务容器。
k8s 部署示例:
# prome-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
# 由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们必须确保在容器内可以看到宿主机上的一些状态信息,为此我们做了两件事
# 第一:配置了如下三条Pod安全策略为 true,确保在 pod 内可以访问到宿主机上的 PID namespace、IPC namespace 以及主机网络
hostPID: true
hostIPC: true
hostNetwork: true
# 第二:将主机的 /dev、/proc、/sys这些目录挂载到容器中,物理节点的很多数据都在这些目录中
volumes:
- name: proc
hostPath:
path: /proc # top命令查看到的cpu状态就来自于/proc/stat, 命令free -h看到的内存状态就来自于/proc/meminfo
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
# 此外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍
# 下面这条容忍设置的含义是:无论节点上存在何种 Taints,该 Pod 都会容忍这些 Taints,从而能够分布到所有节点上。
# 这是确保监控工具 DaemonSet 可被部署到 Kubernetes 集群所有节点上的常见做法。
tolerations:
- operator: 'Exists'
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: quay.io/prometheus/node-exporter:latest
# 选项定制详见:https://github.com/prometheus/node_exporter
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
# 禁用不需要的一些采集器
- --no-collector.hwmon
- --no-collector.nfs
- --no-collector.nfsd
- --no-collector.nvme
- --no-collector.dmi
- --no-collector.arp
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true 添加监控项:
- job_name: "node-exporter"
static_configs:
- targets: ["192.168.2.201:9100","192.168.2.202:9100","192.168.2.203:9100","192.168.2.211:9100","192.168.2.214:9100","192.168.2.218:9100"]
kubectl apply -f prometheus-cm.yaml
curl -X POST "http://10.244.4.8:9090/-/reload"7.2 动态发现示例
Prometheus 监控物理节点自动发现示例:
scrape_configs:
- job_name: 'kubernetes-nodes' # 任务名称
scheme: http # 协议,http 表示使用 HTTP 协议。如果你的 Node Exporter 配置了 HTTPS,则需要改为 https。
kubernetes_sd_configs: # 使用Kubernetes服务发现
- role: node # 它指定 Prometheus 去查询 Kubernetes API,获取集群中所有 Node 节点的列表。每个节点对象都会成为一个潜在的被抓取目标。如果 Prometheus 在集群外部署还需要指定 API Server 地址和认证信息。
# 当 role: node 时,Prometheus 默认会为每个节点生成一个目标地址:<NodeInternalIP>:10250(10250 是 kubelet 的默认端口)。
# 重写标定规则:因为我们发现的是节点,但Node Exporter的端口是9100
relabel_configs:
# 1. 将 __address__ 从默认的 node:10250 替换为 node:9100
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
# 2. 将 Prometheus 自动发现机制获取到的所有 Kubernetes 节点标签,映射为 Prometheus 自身的标签,这样在查询监控数据时,你可以使用节点的标签进行过滤、分组和聚合
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
kubectl apply -f prometheus-cm.yaml
curl -X POST "http://10.244.4.8:9090/-/reload"