1. MySQL 体系结构
MySQL数据库的体系结构如下图所示:
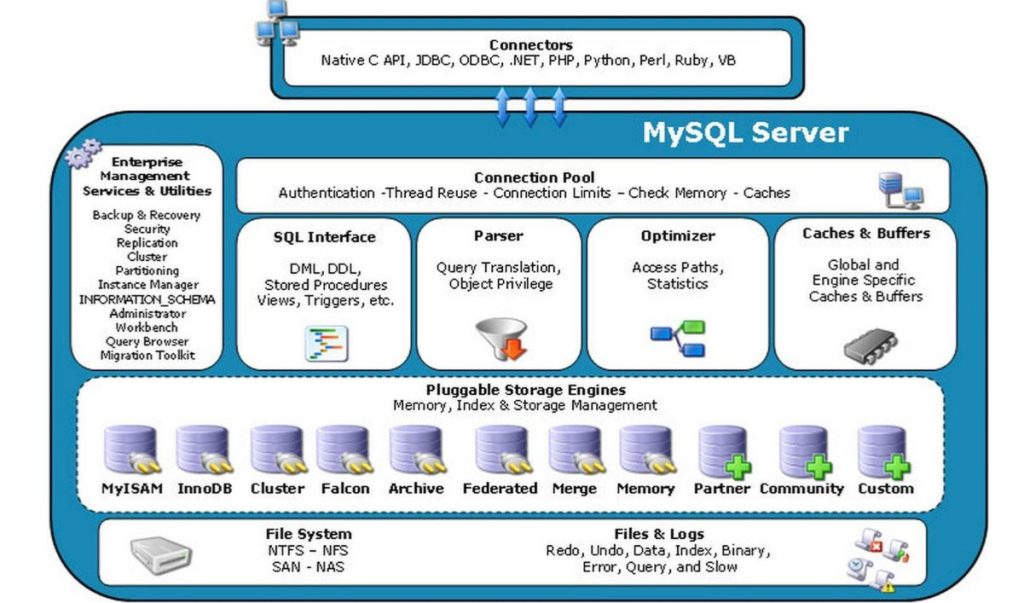
- 客户端层
- 客户端连接器(Connectors)包括各种客户端程序和连接工具,如命令行客户端 mysql、图形界面工具(如MySQL Workbench),以及通过网络或本地 socket 与 MySQL 服务器建立连接的应用程序接口(APIs)。
- 连接层
- 连接池组件(Connection Pool)当客户端请求连接MySQL服务器时,负责管理这些连接。它包括连接池管理(处理新的连接请求、复用现有连接)、验证客户端的权限(通过用户名和密码),以及处理连接断开或错误。
- SQL层
- SQL接口(SQL Interface)接收用户输入的SQL语句。
- 解析器(Parser)分析SQL语句的语法。
- 查询优化器(Optimizer)选择执行查询的最佳方式。
- 缓存(Caches&Buffers)(在MySQL 5.7及之前的版本中)暂存常用查询的结果。
- 存储引擎层
- 插件式存储引擎(Pluggable Storage Engines)MySQL支持多种存储引擎,每种引擎都可以有不同的性能特性、支持的功能(如事务处理或全文搜索)和用例。
MySQL 查询流程图:
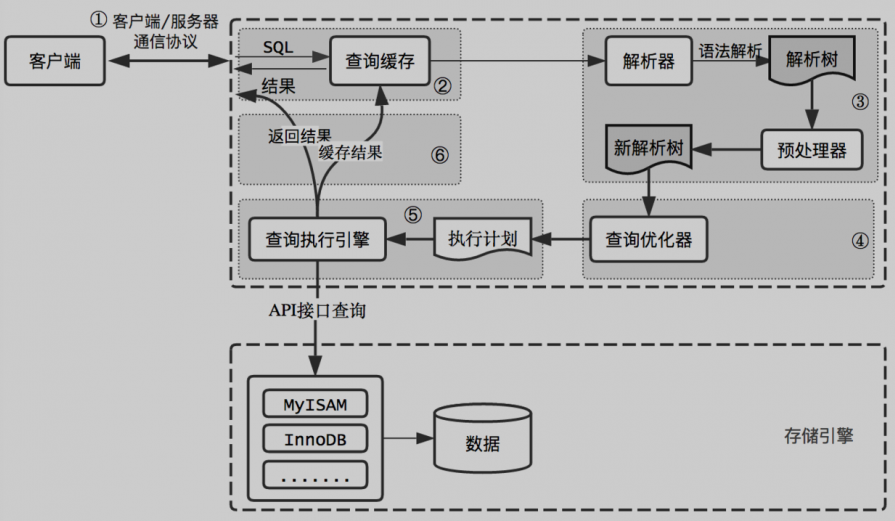
2. MySQL 常见存储引擎介绍
2.1. InnoDB(默认引擎)
- 特点
- 事务支持:支持 ACID 事务(
COMMIT/ROLLBACK)。 - 行级锁:提高并发性能,避免表锁冲突。
- 外键约束:支持外键(Foreign Key)。
- 崩溃恢复:通过日志(redo log)保证数据安全。
- 聚簇索引:数据按主键顺序存储,提高范围查询效率。
- 事务支持:支持 ACID 事务(
- 适用场景
- 高并发事务(如电商、支付系统)。
- 需要外键或事务的 OLTP(在线事务处理)应用。
2.2. MyISAM(旧版默认引擎)
- 特点
- 表级锁:读写操作会锁整个表,并发性能差。
- 无事务:不支持事务和崩溃恢复。
- 全文索引:支持
FULLTEXT索引(适用于文本搜索)。 - 高速读取:适合读多写少的场景。
- 适用场景
- 只读或读多写少的应用(如日志分析)。
- 需要全文索引的简单查询。
- 缺点
- 数据损坏风险高(崩溃后可能无法恢复)。
- 逐渐被 InnoDB 替代(MySQL 8.0 后已不再增强)。
2.3. Memory(内存引擎)
- 特点
- 数据存储在内存:读写速度极快,但重启后数据丢失。
- 表级锁:并发性能受限。
- 不支持 BLOB/TEXT 类型。
- 适用场景
- 临时表或缓存数据。
- 高速临时计算(如会话存储)。
2.4. Archive(归档引擎)
- 特点
- 高压缩比:数据压缩后占用空间极小。
- 仅支持插入和查询:不支持更新/删除(通过
INSERT+SELECT模拟)。 - 行级锁:但仅对插入有效。
- 适用场景
- 日志或历史数据归档(如审计日志)。
- 需要低成本存储大量冷数据。
2.5. NDB(集群引擎)
- 特点
- 分布式存储:支持 MySQL Cluster,数据分片到多个节点。
- 高可用性:自动故障转移。
- 内存+磁盘存储:平衡速度和持久性。
- 适用场景
- 高可用性集群。
- 需要线性扩展的应用。
- 缺点
- 配置复杂,资源消耗高。
3. MySQL 存储引擎配置
3.1. 查看存储引擎相关操作
查看支持的存储引擎:
show engines\G查看正在使用的存储引擎:
SELECT @@default_storage_engine;查看存储引擎有哪些表:
-- table_schema 字段的值即表所在的库
select table_schema,table_name,engine from information_schema.tables where engine='innodb';
select table_schema,table_name,engine from information_schema.tables where engine='myisam';查看表的存储引擎:
SHOW TABLE STATUS FROM 数据库名 LIKE '表名'\G3.2. 配置存储引擎
配置文件指定存储引擎:
[mysqld]
default-storage-engine=innodb
innodb_file_per_table=1临时修改存储引擎:
-- 在MySQL命令行中临时设置
SET @@storage_engine=myisam
-- 查看
SELECT @@default_storage_engine;创建表时修改存储引擎:
CREATE TABLE temp_data (
id INT,
value VARCHAR(100)
) ENGINE=MEMORY;修改表的存储引擎:
-- 使用 ALTER TABLE 语句
-- 修改前先备份
CREATE TABLE 备份表名 LIKE 原表名; -- 精确复制表结构
INSERT INTO 备份表名 SELECT * FROM 原表名; -- 复制数据
-- 修改表的引擎
ALTER TABLE 表名 ENGINE=InnoDB;